It’s been years since I was first warned how important a good data design is. As reminded recently by one senior engineer I know, data is very likely to outlive software. By a long time.
From this perspective, data design may sound a bit scary. It might sound pretty demotivating. As in – how do I design the data part, so that it can be effectively used years after I am no longer working there. This is a proper challenge. It is not uncommon that new, shiny, greenfield systems are being built around legacy data schemas, created years ago, just because it is very, very complicated to move into a new data schema.
Yet, albeit this scary scenario is common, there are other risks lurking around. Even if you had not decided to build new tech, using old data. The common one would be DB engine upgrades. Whether you are in the relational database world or in the less structured world of so-called no-sql databases. An engine just became obsolete, or you’d like to apply that new, shiny security feature. And all of a sudden you need to report that it will take a longer while. Just because the new database system might be no longer supporting a feature your whole original code was based on.
The usual and potentially simple answer to this, is skipping the usage of database-system proprietary features. Design it as simple as possible. Though will it work fast? Will it be reliable? Then again, at the point you are selecting the engine, you can’t really predict the future of what will become proprietary and what will become a standard. The right answer is, you need to learn treating your data like you treat your code. And if you can’t apply proper design to your data, you at least need to apply this to either the data structure, or the interfaces your database system communicates with the external world.
Much too often data and data access is being treated as a second class citizen. The fact is, that data is in many cases more important to your company to what you can do with it.
I’m a huge proponent of designing your code around the data, rather than the other way around, and I think it’s one of the reasons git has been fairly successful… I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important. Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
Linus Torvalds https://lwn.net/Articles/193245/
One approach in not having the data structure problems is to keep it in unstructured, cloud-based solutions. Where updates to the engine guarantee (to some degree) compatibility.
I still remember my first attempts to use MongoDB and unstructured data. Originally unstructured solutions did not have enough technical capability. Relational databases offered a readily-available, stable and simple solution. Worth to note cloud computing wasn’t popular either. What was popular? Categorisation and, strong-typing data and rules. Rules were safe. But strict categorisation, strict rules and risk-averse approaches were proven wrong multiple times over the course of the history.

Coincidentally relational solutions were based on this very non-natural concept of strictly categorising data objects and documenting links between them explicitly. Like an army structure or straight-white-male-vs-others culture of XIX century. These rules were designed to keep the status quo. Even when the original problem stopped to exist. We have modified our society and the average user-experience of a typical person is much more rewarding than back then. We can do the same to tech.
Going further into UX considerations. In the real life, how many times would you: describe what a sock is to accept it, index your socks, apply fitting containers for your socks or write down which socks go well with which jumpers and trousers? Generally speaking you dump your clothes into a wardrobe, using keys like hangers for shirts or drawer for socks/undergarments. Some, would also dump their clothes on the floor, chairs, etc (you can call it a cache :) ). You may say your room is a gigantic data store. You allow your brain to dynamically pull what suits you when you need it, at the same time push it anywhere, to any container.
Do we still need to keep to these concepts? It is a question worth asking a lot, especially when building software.
Attempting to avoid this imposed structure altogether with solutions like AWS S3, event streams or kafka is one idea to keep the data element being better managed.
But let’s say you have already decided, or just inherited a system that is using RDS. Migrating all your business applications to a new data store might be not something your business stakeholders want to hear about. Yet not all is lost for you. Some would say RDS still has the advantage over the newer approaches precisely because of its structure. It will potentially be much easier to find a developer understanding SQL, rather than a developer knowing how to partition data in parquet.
I have mentioned above to treat your data as you would treat the code. This basically means:
- using principles like DRY and SOLID
- naming conventions
- good documentation
- having a version control tool
- validate for what you would not like the developers to use (avoid bespoke problem solutions and use good practices)
Understanding how to apply DRY and SOLID to data schema design will require practice. It is not knowledge that is prioritized in developer communities. I personally know a few people who had managed to build a good RDS schema design. In most cases only because they built something bad first. It was an acquired, practical knowledge. I do like to listen to them. I learn a lot each time.
The rest can be enforced by introducing schema / data migration tools. I have had the most experience with liquibase. Though flyway is a similar product. These tools allow you to apply, store and validate to the data schema, as if you were using a version control, documentation and verification and validation tool for the code. Version history is in most cases stored in your DB in a separate migration tool schema (rather than a repository like gitlab).
For an example use-case, I have created this repository (which is being shared thanks to my employer – Zoopla). It showcases how you could use a dockerized liquibase to manage migrations. The concept is that you describe and schedule your changes using a changeset file (similar to flyway sql migration files). You can add comments and a lot more meta-data. All of it will be stored for future generations. In terms of schema, it will also preserve the history, so you can always re-build your db schema from a scratch. You can read more in the repo and links on the capabilities.
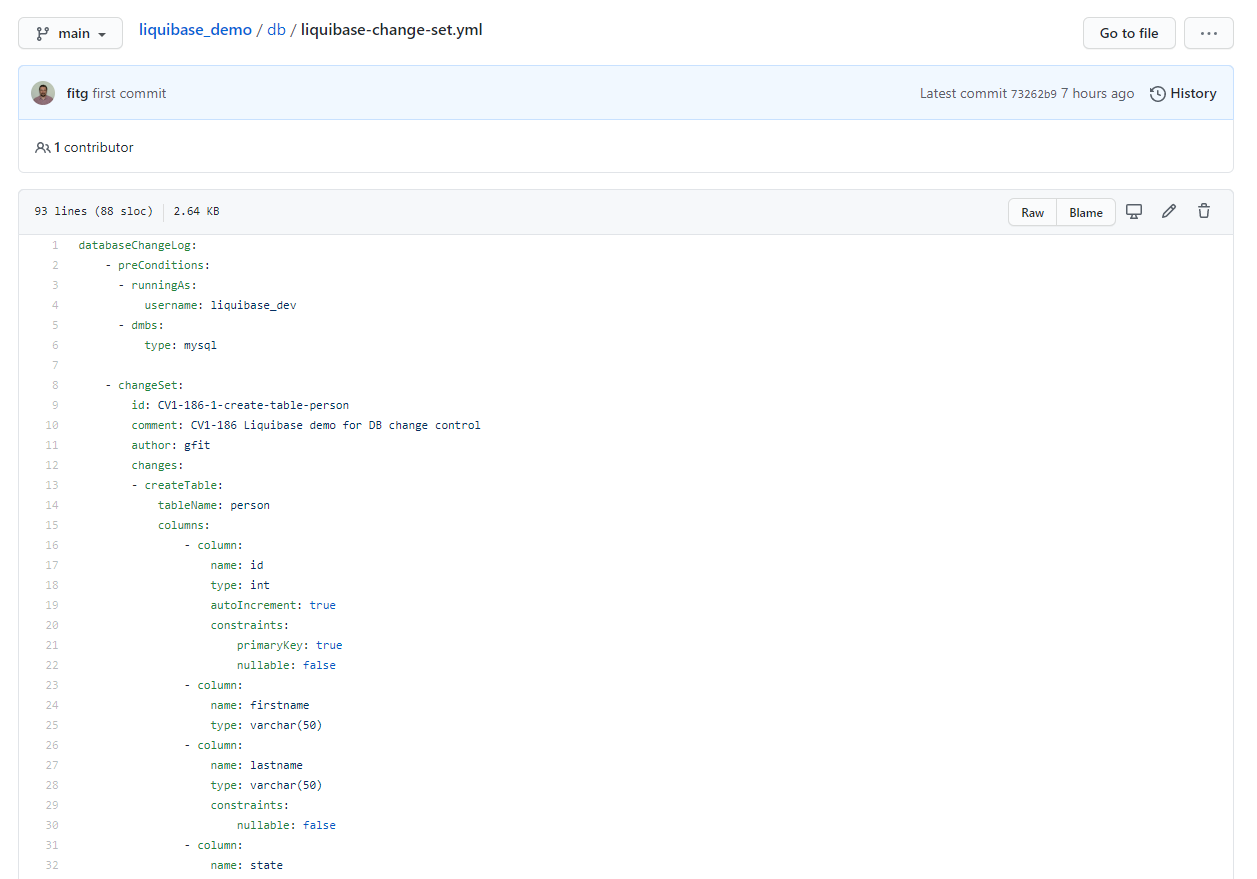
The two chapters above deal with the schema or schema-less. What about the data though? How to manage data reasonably?
The only answer I found are regular backups or using a reasonable replication approach. Note though, that the more complex your management of data, the more complicated your application software change and data migration release will become.
I know of 4 patterns, how to manage migrations on the application release (each having its own problems):
- Use a nosql DB: release app code compatible with previous data version, backfill / replace all objects to follow new schema
- Use a nosql DB: release app code compatible with previous data version, drop transactional-live data store, application DB will backfill objects from a kind of warehouse and enrich in both places on first execution
- Use an RDS DB: use feature flags, disable ff, release app code compatible with previous data version, migrate data schemas, enable feature flag
- Use an RDS DB: release app code that holds data compatibility forever
I have also tried a few approaches with swapping DB replicas, still the code must have been introducing non-breaking changes.
I have never found a good answer to long-running backfills or index modifications though. Can still remember one table with 80 fields and probably 7 indexes, that took 8h to unlock after a column was modified :).
When you are building your pipeline steps, no matter if in maven, gitlab or Azure pipelines (or any other solution), it is highly advised to separate off db migration and software release steps.
“The computer programmer is a creator of universes for which he alone is the lawgiver. No playwright, no stage director, no emperor, however powerful, has ever exercised such absolute authority to arrange a stage or field of battle and to command such unswervingly dutiful actors or troops.”
Joseph Weizenbaum, the creator of ELIZA
With this great power, I highly encourage you to read and learn more on the importance of data structures, different kinds of databases and typical problems. I also tell you to strongly consider implementing how you would be managing data/schema migrations into early versions of your software. It is an area omitted pretty frequently and causing big issues with the same frequency.
I have not found any studies properly reviewing the cost of bad data design and omissions like no schema migration automation, validation, etc. I would be interested to perform one. There is however a lot of material in places like stackoverflow, where you can find pages and pages of software engineers asking questions on how to deal with data more effectively. Like these 803 pages of results: https://stackoverflow.com/search?q=schema+migrations.
To summarize the problems for you:
- Data will outlive the software
- Managing changes to data schema can be hard
- A good data schema design is a rare treat
To summarize some of the suggested solutions:
- Using nosql, cloud managed data stores
- Using data/schema migration tools like liquibase or flyway
- Applying same engineering practices to data you would apply to code (DRY, SOLID, etc)
- Treating a data schema change as you would a software change
That’s it for today. Thank you and see you next week!

Leave a comment